Reflections from a virtual workshop conducted by ESR 4
As foundation AI models (such as large language models and generative AI) are becoming more commonplace, it is also important to study the data sources used to build and train these data-intensive technologies. The quality of training data is significant determiner of the quality and accuracy of the outputs of these AI models. And one important source of training data is the open web – which includes data in the digital public domain, openly licensed data and content, as well as data that is publicly-accessible but may be subject to certain legal rights (like contracts, copyright and data protection).
Despite being the ‘open’ web, data and content on the open web is not ‘open’ for full and free re-use by all. Data and content from the open web is re-used by big technology companies to train proprietary AI models, with little to no value being provided by these actors back into the open web ecosystem or for maintaining open data resources. Cultural resources made available via the open web are also being appropriated by these actors, exacerbating digital colonialism. At the same time, content creators are increasingly adopting restrictive interpretations of intellectual property rights to limit techniques like web scraping, which can be helpful in limiting extraction from the open web by large technology companies, but also adversely impacts other stakeholders such as researchers who rely on web-scraped data. In other words, the ‘openness’ of the open web is facing new risks and challenges.
The Centre for Internet and Society of the CNRS (CIS-CNRS), together with support of Inno3 (an ODECO Partner Organisation) and the Open Knowledge Foundation, organised a 3-hour virtual workshop on November 23, 2024. The objective was to bring together practitioners, researchers and civil-society organisations working on AI, open data and open-source to discuss two questions: (i) what are the legal frictions involved in the re-use of data from the open-web to train foundation AI models, and (ii) what data governance strategies (including legal, technical and social measures) can help address these frictions and enable responsible re-use of open web data. This workshop builds on research undertaken by Ramya Chandrasekhar (ESR 4) during her ODECO professional secondment with Inno3 in 2024.
The workshop saw participation from individuals working in South Africa, USA, Canada, France, Germany, Singapore, Poland, Italy and United Kingdom. Some of these individuals were also involved in developing new licensing frameworks for AI training datasets. The workshop was very interactive, with participants undertaking discussions in both break-out rooms and during plenary. The break-out rooms were facilitated by Ramya Chandrasekhar of CIS-CNRS and Celya Gruson-Daniel of Inno3.
Participants identified many types of legal frictions – relating to copyright, data protection, website terms of use, compliance with open licenses, proliferation of open licenses, and training data transparency. The participants used a miro board, to identify the specific stages in the AI lifecycle where each legal frictions manifests.
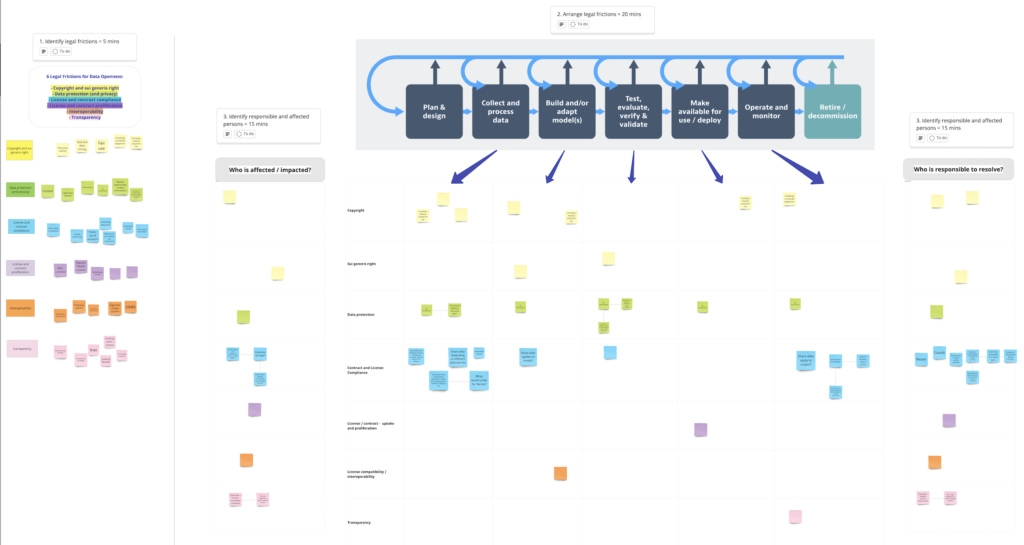
The workshop also yielded several illustrations of data governance initiatives – ranging from new licensing frameworks, new institutional structures for data re-use, and new technical measures such as web protocols for registering opt-outs from web-scraping.
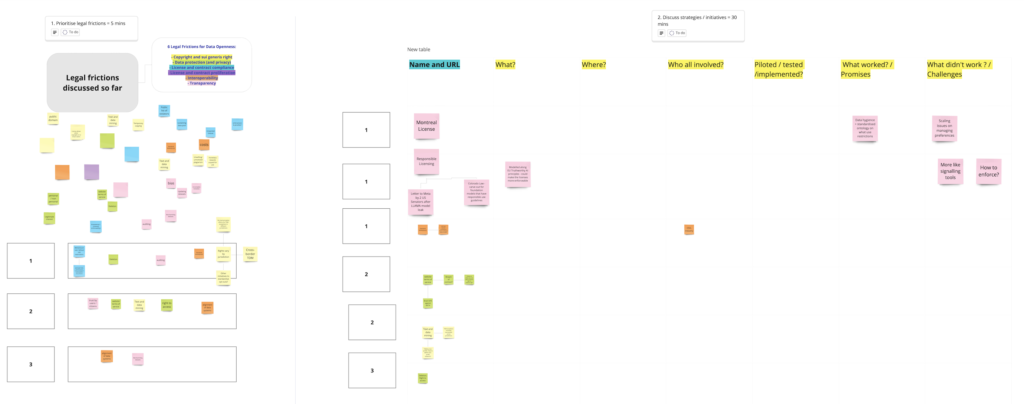
The inputs from the workshop will feed into a public report authored by Ramya Chandrasekhar. Stay tuned for more!
